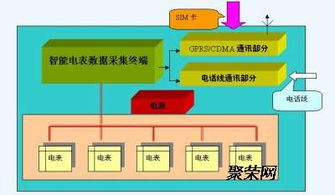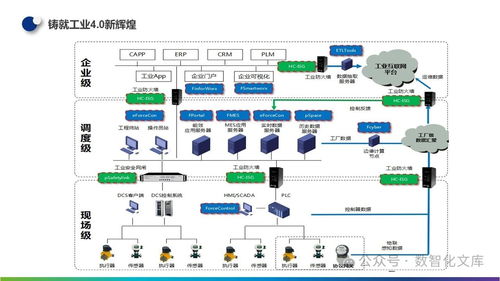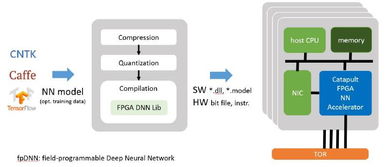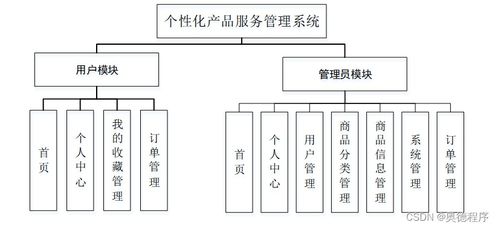
在大数据时代,数据已成为驱动社会发展的核心要素。面对指数级增长的数据量和日益复杂的处理需求,传统集中式架构已显得力不从心。分布式架构以其独特的优势,正在重塑数据处理的新范式,展现出令人惊叹的技术之美。
分布式架构的核心特征
分布式系统的核心魅力在于其将计算任务分散到多个节点上协同完成。这种架构具备三个显著特征:高可用性、水平扩展性和容错能力。通过多节点冗余设计,系统能够在部分节点故障时依然保持正常运行;通过增加节点数量,系统可以线性提升处理能力;通过数据副本和故障转移机制,确保数据安全和处理连续性。
数据处理的技术演进
分布式数据处理经历了从批处理到流处理的演进历程。以Hadoop为代表的批处理框架,通过MapReduce编程模型实现了海量数据的离线分析;而以Spark、Flink为代表的流处理框架,则实现了数据的实时计算和即时响应。这种演进不仅提升了数据处理效率,更拓展了数据应用的边界。
架构之美:弹性与智能
分布式架构最令人称道的是其弹性设计。系统能够根据负载动态调整资源分配,实现成本与性能的最优平衡。现代分布式系统融入了智能调度算法,能够自动识别数据热点、预测负载趋势,并优化数据布局和任务分配。
典型应用场景
在电商领域,分布式架构支撑着秒杀活动的高并发交易;在金融行业,它确保着实时风控和欺诈检测;在物联网应用中,它处理着海量设备产生的时序数据;在内容推荐系统中,它实现着个性化推荐的毫秒级响应。
挑战与未来
尽管分布式架构展现出强大优势,但也面临着数据一致性、网络延迟、系统复杂度等挑战。CAP理论提醒我们,在分布式系统中需要根据业务需求做出合理取舍。随着边缘计算、Serverless架构等新技术的发展,分布式数据处理将向着更智能、更高效的方向演进。
分布式架构不仅是一种技术方案,更是一种设计哲学。它教会我们如何通过分工协作、冗余备份和智能调度,构建出既强健又灵活的数据处理系统。这种架构之美,正是数字化时代最动人的技术诗篇。